
Prediction of Air Quality through Greenhouse Gas Emissions
Greenhouse gases from human activities are the most significant drivers of observed climate change since the mid-20th century. The mid-20th century has seen been accompanied by rapid industrialization and urbanization leading to a rise in global temperatures and air pollutants. This rise in temperatures has been termed global warming by climate scientists.Not suprsingly, several studies are being condicted utilize machine learning techniques to develop accurate climate models and forecasts of the global atmosphere. Our project aims to assist the climate scientists by constructing a reliable statistical model to understand the correlation between greenhouse gas emissions and global warming.
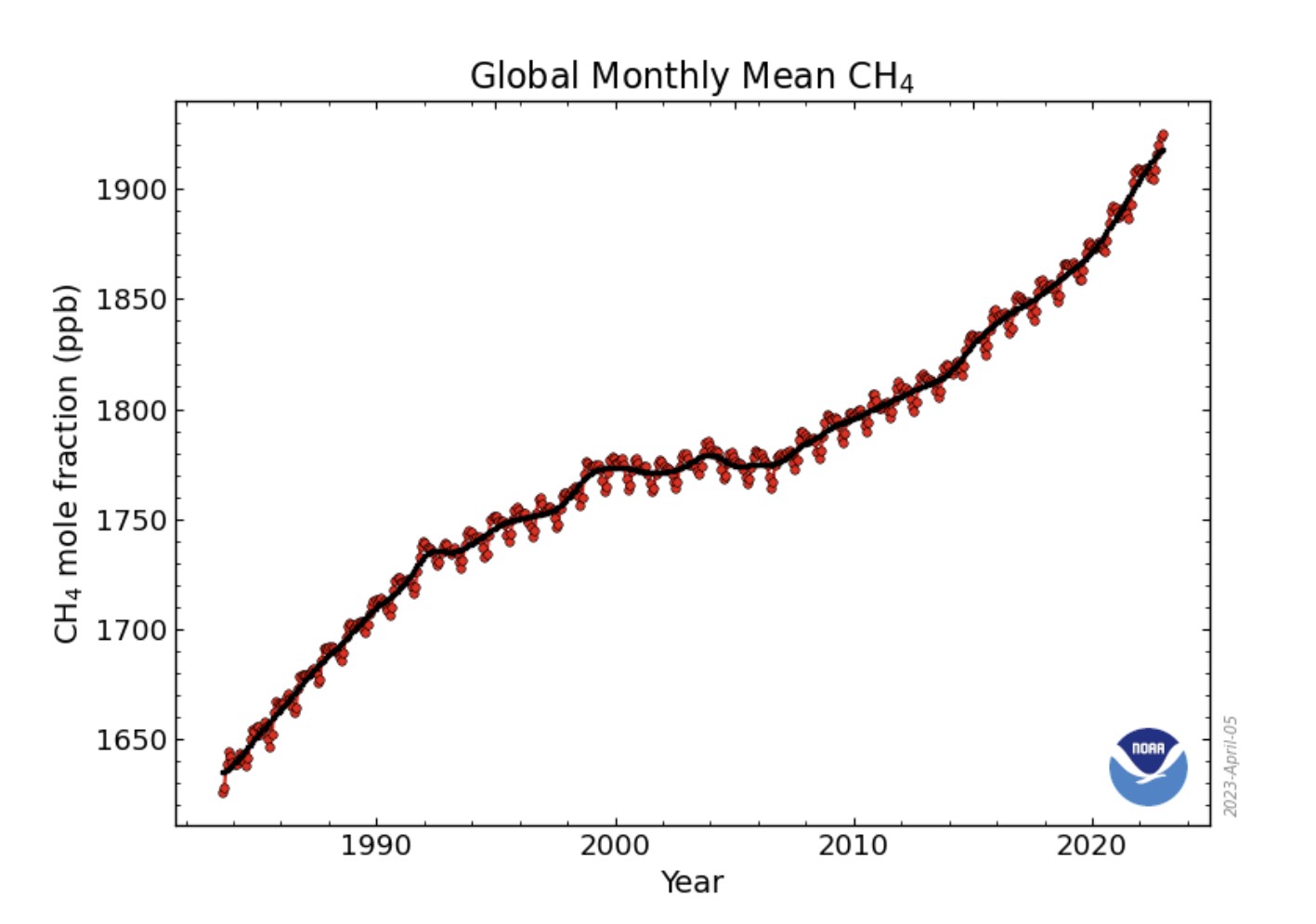
Our study compared the performance of several mainstream machine learning algorithms on our data, which includes Support Vector Regression, Artificial Neural Networks, and Random Forest, to build a novel weather forecasting system. These algorithms were chosen based on their novelty in solving problems with non-linear, time-series datasets. The global greenhouse gas emission data for CH4, CO2, and N2O for the past four decades have been compiled and tabulated in public databases, by environmental agencies such as the National Oceanic and Atmospheric Administration and the United States Environmental Protection Agency.
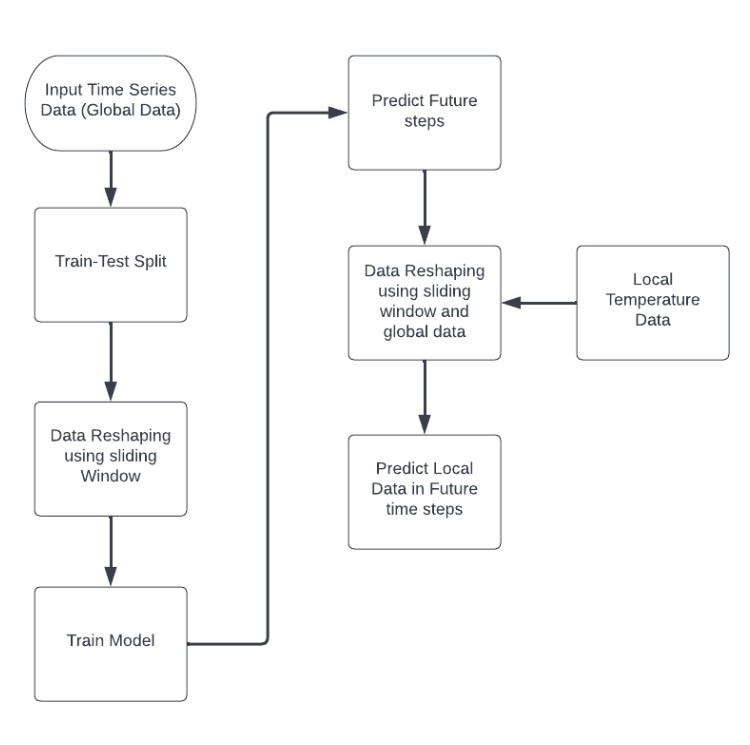
For the scope of our project, only CH4 and CO2 datasets were consdered due to their availability for longer. Furthermore, the Global Temperature anomalies are found on the National Aeronautics and Space Administration (NASA) climate page. The core idea of our study is to forecast future Pittsburgh temperatures using the global Methane (CH4) and Carbon dioxide (CO2) emissions and global temperature anomalies as input features. This is performed as a univariate time-series data with monthly average temperatures. First, the entire data is split according to the number of monthly values assigned for training the model and the number of monthly values assigned for testing. The split data is then used to predict future temperatures using a sliding window technique, where (n+1)th day’s temperature is predicted using the temperatures of the past n number of days. Finally, the future temperatures are predicted by developing a statistical model using the proposed machine learning algorithms.

As a part of this project I used Machine Learning techniques like SVM, ANNs, and Random Forests to forecast the effect of Greenhouse Gas emissions on air quality in Pittsburgh. As mentoned before the core idea was to predict how local temperatures are affected by global gas emissions, and these predictions from one model (eg. SVM) were compared with other models (eg. ANNs and SVM). Moreover, We performed two experiments to test the accuracy of our model.For the first approach we used a sliding window which was used to directly predict future values. Second, the predicted temperature values are appended back to the dataset and are utilized for future predictions. However, we noticed that predicting the future beyond the available data led to innacurate results and concluded our appraoch was not enough. A second approach was developed where for predicting the future beyond the available data requires adding the prediction back to the data and predicting based on the new data. Surprisingly, we observed our predictions were distinctly wrong. For SVM/SVR we found the Mean Absolute Percentage Error for the first approach to be around 7.32%. For the second approach, we found the Mean Absolute Percentage Error to be very large around 37.77 %. Next for Random Forest, the testing gave us 7.56% Mean Absolute Percentage Error, and the test on the data by adding the prediction back to the dataset to predict gave us 15.69% Mean Absolute Percentage Error. In contradiction to our expectations, using Artificial Neural Networks showed worse performance.
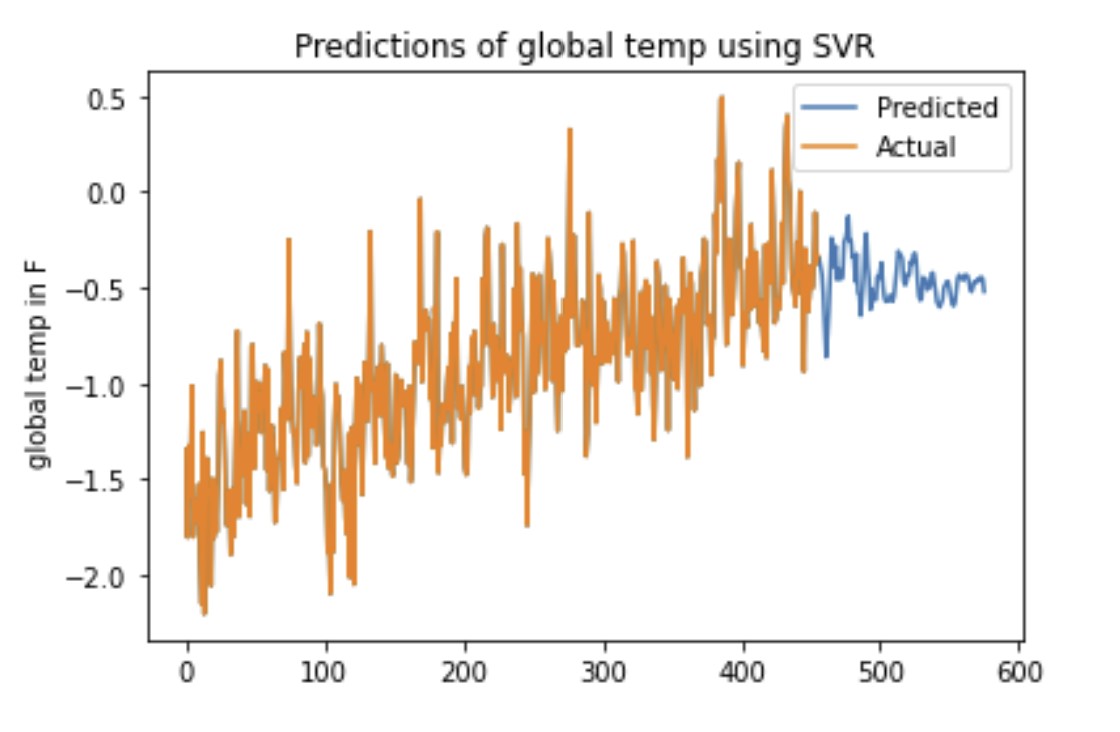
Our teamfound that random forest outperforms other algorithms to create accurate climate models. Our models use concentrations of different greenhouse gasses as features to precisely forecast the Pittsburgh atmosphere. The accuracy of our model was strongly reliant on the size of the sliding window. However, we observed that while the models were able to accurately predict the testing data, they failed when we were trying to forecast future temperatures. Among our three models, the best results were from using the Random Forest Regressor with a Mean Absolute Percentage Error of around 15.69%.