
Dense Video Captioning with Semantic Alignmnet
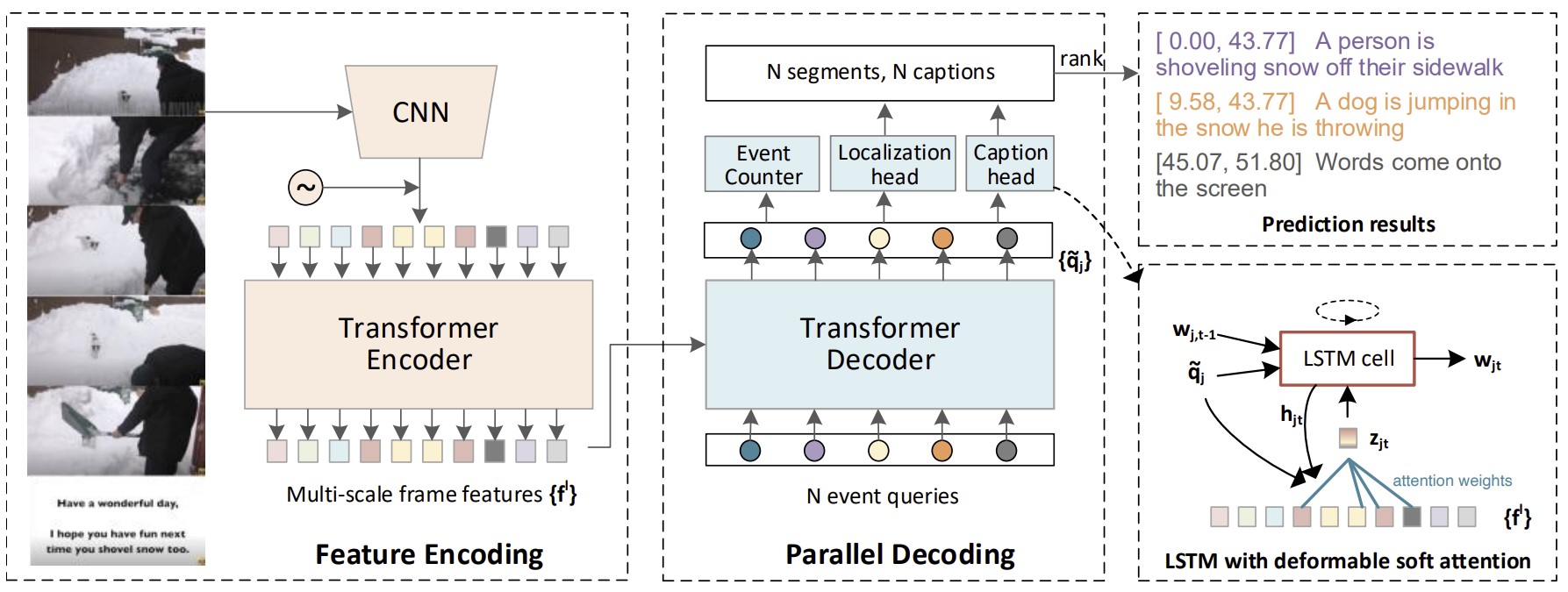
In recent years, there has been a large research focus on dense video captioning. Video captioning has applications in many fields such as autonomous driving, video surveillance and creating captions for those with visual impairments. It can aid those with visual impairments, self-driving cars, caption surveillance and even automatically labeling data. Providing meaningful captions videos not seen during training happens to a major hurdle faced by current state of the art video captioning models. Current SOTA dense video captioning model, dense video captioning framework with parallel decoding (PDVC) produced strong results compared to other video captioning frameworks but can still be improved. In order to improve PDVC, the addition of semantic alignment holds much promise. Semantic alignment refers to the process of aligning the visual and caption features such that they are similar in the embedding space. The proposed semanitic alignment is incorporated through the addition of a tuner network trained on a contrastive loss with caption embeddings generated through a pre-trained Langugae Model. This Tuner is then placed before the video features are passed through the PDVC framework.
The idea of using a tuner to semantically align visual and caption features was inspired from Contrastive Language-Image Pre-Training (CLIP) is a powerful model that combines a large-scale transformer-based language model with a convolutional neural network (CNN) for visual processing and is centered on learning perception from supervision contained in natural language. CLIP jointly trains an image and text encoder for the occurrence of possible image-text pairings across a batch and during testing the learned text encoder synthesizes a zero-shot linear classifier by embedding the names ordescriptions of the target dataset’s classes. Since CLIP trains a text and image encoder simultaneously to align their embeddings, its text encoder is ideal for semantic alignment.
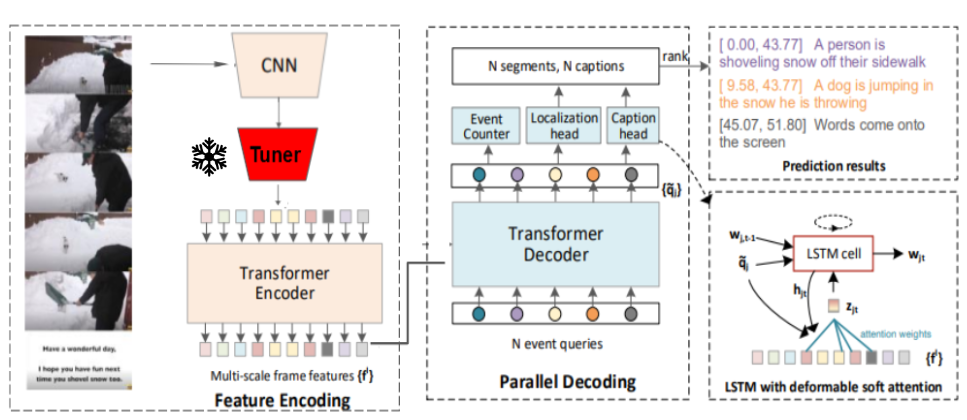
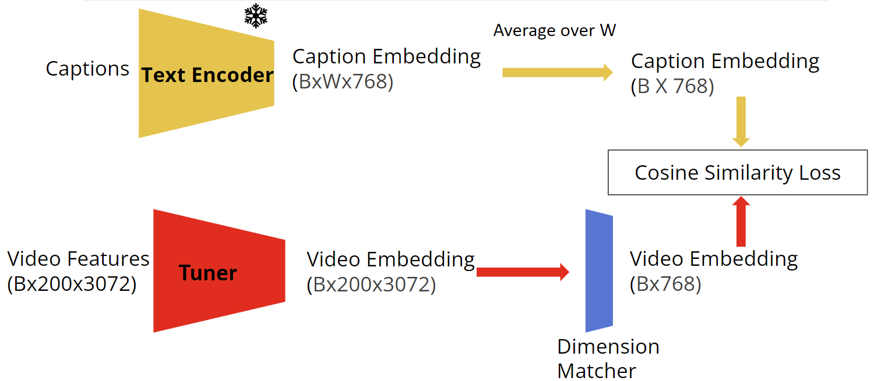
In the modified framework, the video captions are fed directly into CLIP’s frozen pre-trained text encoder. Simultaneously, the extracted video features are fed through a neural network called the video feature tuner. The output of this tuner and the text encoder are compared through a cosine similarity loss in order to align their outputs and this loss is used to update the video feature tuner weights and trained. Once this training is completed, the video feature tuner is frozen and inserted into the PDVC. Our hypothesis was that this tuner incorporate some information from the CLIP text encoder into the video feature embeddings of unseen videos. With this addition, the overall PDVC framework is trained from scratch using YouCook2 to see whether some degree of semantic alignment was achieved. The performance of the model is then evaluated with the same metrics as the PDVC baseline:BLEU4, METEOR, CIDEr, and SODA_c.
The table above shows the different ablation study each memeber of the team has run with different architectures.Each member ran ablations four architectures and fthe final score was computed by averaging idnividual scores. It was observed that Linear, Conv1 and Conv1 w/ Linear all outperform the baseline PDVC in at least three of the given metrics. In fact, Conv1 outperforms the baseline PDVC in all four metrics BLEU4, METEOR, CIDEr, and SODA_c by 18.4%, 3.2% , 8% and 0.6% respectively. This suggests that it has unilaterally improved the precision, recall and also the overall story telling capabilities of PDVC.
| Architecture | BLEU4 | METEOR | CIDER | SODA_c |
|---|---|---|---|---|
| Baseline | 0.76 ± 0.05 | 4.39 ± 0.07 | 20.68 ± 0.21 | 4.47 ± 0.87 |
| Linear | 0.87 ± 0.06 | 4.74 ± 0.09 | 21.76 ± 0.04 | 4.45 ± 1.13 |
| Conv1 | 0.90 ± 0.02 | 4.53 ± 0.07 | 22.32 ± 0.05 | 4.50 ± 1.48 |
| Conv1 with Linear | 0.77 ± 0.15 | 4.48 ± 0.02 | 21.07 ± 0.92 | 4.47 ± 1.49 |
| Conv2 | 0.40 ± 0.08 | 3.35 ± 0.01 | 14.34 ± 0.02 | 3.53 ± 0.71 |
In conclusion, our study demonstrated the significant impact of semantic alignment on the performance of dense video captioning. Specifically, models trained with semantic alignment can achievehigher scores across all evaluation metrics, indicating better overall performance in caption generation.However, a high observed variance between the metric scores of models was noted, which could be attributed to the limited dataset size of YouCook2. This suggests that further research is needed to determine the optimal training data size and quality needed to achieve consistent performance across different metrics. In addition, it is directly shown that an improperly trained and constructed tuner model such as Conv2 can hinder the performance of PDVC across all evaluation metrics, stressing the importance of investigating optimal tuner model architectures. Nevertheless, this project highlights the importance of considering semantic alignment when generating video captions. Additionally, the results provide insight into the strengths and weaknesses of different architectures and evaluation metrics for dense video captioning, which could inform the development of more effective models in the future.